附:为什么发布服务器的load较高,原因是发布服务器跑了一些日志收集,数据分析,以及“被作为12台”服务器监控,所以load相对较高。 目前因为这次调整,load已经基本维持在1以下,偶尔最高达到2。

最近,手头某一省级平台发生系统反应缓慢,一个请求可以达到五六秒,极大影响系统的体验。客户反应巨大。着手解决这个问题,但是解决的过程很鸡血,实在是痛苦。
架构模式:Share-nothing架构,Browser->WebServer(即App server)->DB。Web(应用)服务器完全无状态,可实现热插拔;客户端采用AJAX替代传统Web页面。
架构组成:8台中低端PC服务器(Dell R510),16个Jetty实例;同时,8台PC服务器也兼了Cache服务器,总共开辟出16G缓存;2台反向代理集群,缓存资源文件;2台IBM小机,互为热备,作为DB(数据库未实现shard)。
架构设计容量:5万注册用户,1000左右的并发。
2、考虑DB压力不大,那么一下应用服务器的压力是否过重,看了一下所有服务器的load,发现最大也不过6左右,而且,每台应用服务器的Load图表都差不多(注1),应用服务器都有8个核心,Load都未到8,虽然load值偏大了(1/10的用户量),但应该不至于使系统反应如此缓慢呀。这下头大了,系统的load偏高,此其一;但系统反应缓慢,Load的表现和系统表现不一致,此其二.

3、由于用户基数和请求数的现实,考虑是否网络流量过大,由于是AJAX应用,又考虑资源文件请求和网络流量的问题。于是,查看了反向代理服务器的Load和流量,以及整个系统的流量。木有发现什么问题!
A) 反向代理服务器的Load

B) 反向代理服务器的流量
C) 系统流量
这下麻烦了,IO,NetWork IO,Load都不能体现系统的实际状况,那问题难倒出现在JVM内部? 可是JVM内存正常! CPU正常!
唉,只能使用最原始的办法了,分析日志.....最痛苦也是最有效的方式。
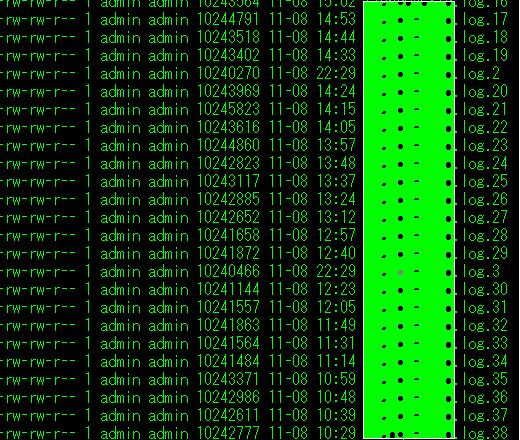
2) 系统访问日志分析:
cat jetty-2011_11_18.request_.log | awk '/18 11:[3-5]/{print}' | awk '{print $7}' | awk -F '?' '{print $1}' |sort | uniq -c | sort -nr | head -n 100
上述语句的意思是,对11月18日11点30至12点之间的访问的URL,打印访问数量排名前100的数量以及URL.
分析得到这段时间内产生的访问都属于正常访问,未见有异常的访问(之前,对于这些URL已经进行性能测试冲击,并未发现特别耗资源的,并发量也不错).
死路一条?
咋办? 现在能看得见的就是日志量有些大,对,日志量有些大! 看了一下log4j的配置,全局是info级别记录。根据经验判断,这个是有点多了的,但是多到什么程度?
对app.log.*进行分析:
cat app.log* | awk '/18 11:3[0-4]/{print}'| wc -l
(注:统计18日当天11点30分至35之间的日志行数)
发现, 5分钟打了900多条记录。于是对系统高峰期(10:00--12:00, 13:30~~14:00)进行了抽样调查,发现一个Jetty实例,每秒钟最高日志量能达到200条, 显然两个Jetty实例,每秒钟需要写将近400条的日志。
这是系统的瓶颈了???但是为什么应用服务器的load并不高?如果是IO瓶颈,那么Load应该能反应出来的,可是Load为什么都差不多平均在1以下呢? 我不能确定。
于是,在旁支环境进行了测试,将系统日志级别进行全面调整,仅打ERROR级别及以上的日志。调整前后分别用ab(ApacheBench)对系统某个轻量级请求进行了冲击测试。
A)、在调整前,每秒100,200,300的并发,系统实际吞吐量达到70~80个请求/秒
B)、调整后,每秒100,200,300的并发,系统实际吞吐量能达到800~1000个请求/秒。
肯定是问题所在了!全面调整日志打印参数,提高应用日志打印级别。 系统的性能得到了本质的提高。
可是,为什么系统load和实际反映不一样呢? 当时很晚了,于是回家了。第二天上午,系统人员告诉我,监控貌似有点不对,下午,系统人员告诉我,所有的监控都指向发布服务器了~~~~~~汗~~~~当天即得到了调整,真是杯具,木有历史记录了。
案例分析一例,供各位大虾参考。
附:为什么发布服务器的load较高,原因是发布服务器跑了一些日志收集,数据分析,以及“被作为12台”服务器监控,所以load相对较高。 目前因为这次调整,load已经基本维持在1以下,偶尔最高达到2。
@myth:我当时的现象是小型机存储柜超过了2T的空间, 导致NFS 不稳定 因为我的日志直接写在N...
咔嚓,你都木有仔细看。
@myth:日志级别降低 那就是说程序还是有BUG哦 写的不严密???
日志在系统设计之初就要求较高,在调试阶段输出很详细,在运行阶段,输出则只需要错误输出即可。
